dbt Analytics Engineering Certification Exam
The Analytics Engineering Certification Exam evaluates your ability to:
- build, test, and maintain models to make data accessible to others
- use dbt to apply engineering principles to analytics infrastructure
duration
number of questions
passing score
Price
Supported version
Recommended Experience
- SQL proficiency
- 6+ months building on dbt Core or Cloud
What's covered in the exam?
- Identifying and verifying any raw object dependencies
- Understanding core dbt materializations
- Conceptualizing modularity and how to incorporate DRY principles
- Converting business logic into performant SQL queries
- Using commands such as
run, test, docsandseed - Creating a logical flow of models and building clean DAGs
- Defining configurations in
dbt_project.yml - Configuring sources in dbt
- Using dbt Packages
- Utilizing git functionality within the development lifecycle
- Creating Python Models
- Providing access to users to models with the “grants” config
- Adding contracts to models to ensure the shape of models
- Creating different versions of our models and deprecating the old ones
- Configuring Model Access
- Understanding logged error messages
- Troubleshooting using compiled code
- Troubleshooting .yml compilation errors
- Distinguishing between dbt core or data platform error responses
- Developing and implementing a fix and testing it prior to merging
- Troubleshooting and managing failure points in the DAG
- Using dbt clone
- Troubleshooting errors from integrated tools
- Using generic, singular, custom, and custom generic tests on a wide variety of models and sources
- Testing assumptions for dbt models and sources
- Implementing various testing steps in the workflow
- Updating dbt docs
- Implementing source, table, and column descriptions in yml files
- Using macros to show model and data lineage on the DAG
- Implementing dbt exposures
- Implementing source freshness
- Understanding state
- Using dbt retry
- Combining state and result selectors
Sample Questions
1

dbt test accepts many configuration parameters but not all of them would avoid testing an incremendbt test accepts many configuration parameters but not all of them would avoid testing an incremental model entirely after every run.
The correct answer here is that we could use:
- a where parameter on the test to potentially restrict data for a specific set of dates
Or
- if supported by the data platform, set a contract on the model with a not_null constraint, letting the data warehouse test the new incremental data automatically before it is inserted in the table.
2

If a table consists of a large number of rows and only new data is being added at each run, setting the model as incremental allows dbt to run the transformation only on the new data, saving a lot of time and compute on the data warehouse.
Therefore, the answer is that incremental models are ideal for datasets with millions of rows where data is added but previous rows are not updated.
3

The correct answer is to use git pull . This will actually run both git fetch, downloading the code that has been pushed to the repository, and git merge which will combine the code just fetched with the code in the current branch.
4

dbt recognizes dependencies between models when the ref macro is used. To ensure that accounts.sql model runs after the two other models, every hard coded table in accounts.sql must be replaced with the relevant ref statement.
Therefore, the answer is that the ref macro needs to be set for both the from and join clauses of accounts.sql.
5
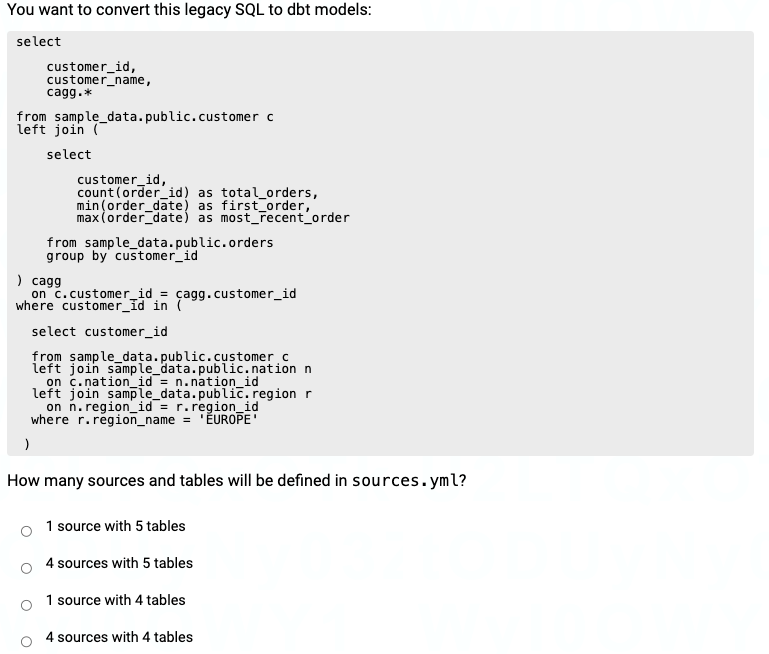
Every source in dbt maps to a database + schema combination. Because the database sample_data and schema public are used on all references, this is one source. Tables are configured within a source’s tables configuration. There are four tables referenced: customers, orders, nations, and regions.